友情链接:
转头昔时两年东谈主工智能的合座逾越...东谈主工智能在好多规模都在快速追逐东谈主类🔥2024欧洲杯(中国区)官网-登录入口,坦率地说,咱们需要新的测试。斯坦福大学以东谈主为中心的东谈主工智能接头所(HAI)发布了第七期年度东谈主工智能空洞指数叙述,该叙述由一个跨学科的学术和工业民众团队撰写。
与前几期比较,本期内容更丰富,反馈了东谈主工智能的快速发展偏执在咱们日常生涯中日益增长的要紧性。从哪些行业使用东谈主工智能最多,到哪个国度最记念东谈主工智能会导致休闲,叙述都进行了接头。但叙述中最凸起的少量是东谈主工智能在与东谈主类竞争时的推崇。
关于没联系注东谈主工智能的东谈主来说,东谈主工智能依然在许多要紧的基准测试中打败了咱们。2015 年,它在图像分类方面特等了咱们,然后是基本阅读走漏(2017 年)、视觉推理(2020 年)和当然谈话推理(2021 年)。
东谈主工智能变得如斯奢睿,速率如斯之快,以致于在此之前使用的许多基准当今都已过期。事实上,该规模的接头东谈主员正在分秒必争地诞生新的、更具挑战性的基准。通俗地说,东谈主工智能通过测试的才气越来越强,以致于咱们当今需要新的测试--不是为了揣摸才气,而是为了凸起东谈主类和东谈主工智能仍有相反的规模,找到咱们仍有上风的方位。
值得细心的是,底下的收尾反馈的是使用这些旧的、可能已过程时的基准进行的测试。但总体趋势仍然至极赫然:
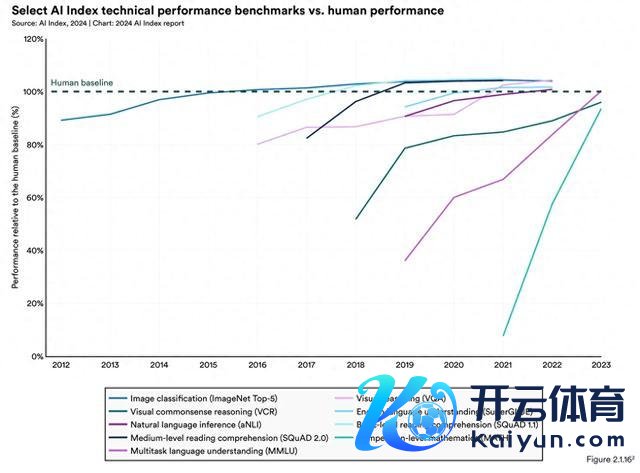
东谈主工智能依然超越了东谈主类的许多性能基准
望望这些轨迹,尤其是最近的测试是如何用一条接近垂直的线来默示的,需要知谈的是这些机器还仅仅踉跄学步的婴儿。
新的东谈主工智能指数叙述指出,到2023年,东谈主工智能在高档数学问题科罚和视觉学问推理等复杂的领略任务上仍将举步维艰。不外,这里的"顽抗"可能会引起误会;这虽然并不料味着东谈主工智能作念得很差。
MATH 是一个包含 12500 个具有挑战性的竞赛级数学问题的数据集,自推出以来的两年中,其性能得到了显耀进步。2021 年,东谈主工智能系统只可科罚 6.9% 的问题。比较之下,在 2023 年,基于 GPT-4 的模子科罚了 84.3% 的问题。东谈主类的基线是 90%。
咱们这里说的不是普通东谈主;咱们说的是能科罚这么的测试题的东谈主:

向东谈主工智能淡薄的数学问题示例
这等于 2024 年高等数学的发展景色,咱们仍然处于东谈主工智能期间的朝晨期。
然后是视觉学问推理(VCR)。除了通俗的物体识别外,VCR 还能评估东谈主工智能如安在视觉环境中讹诈学问性知识进行瞻望。举例,当看到桌子上有一只猫的图像时,具有 VCR 的东谈主工智能应该瞻望猫可能会从桌子上跳下来,或者把柄猫的分量,瞻望桌子饱和舒适,不错容纳猫。
叙述发现,在 2022 年至 2023 年期间,VCR 增多了 7.93%,达到 81.60,而东谈主类的基线是 85。

用于测试东谈主工智能视觉学问推理的示例问题
把想绪拉回到五年前。瞎想一下,即使你想给电脑看一张图片,并守望它能"走漏"高下文,从而回报这个问题。
如今,东谈主工智能不错生成许多行业的书面内容。然而,尽管得到了广大逾越,大型谈话模子(LLM)仍然容易产生'幻觉'。"幻觉"是OpenAI等公司珍贵的一个至极柔柔的术语,大概赞佩是"将虚伪或误导性信息行为事实呈现"。
旧年,东谈主工智能的"幻觉"倾向让纽约讼师史蒂文-施瓦茨(Steven Schwartz)莫名不已,他使用 ChatGPT 进行法律接头,却莫得对收尾进行事实核查。审理此案的法官很快就发现了东谈主工智能在提交的文献中抓造的法律案件,并对施瓦茨的马虎轻佻处以 5000 好意思元(7750 澳元)的罚金。他的故事成为了民众新闻。
HaluEval被用作幻觉的基准。测试标明,对许多当地谈话学习者来说,幻觉仍然是一个要紧问题。
真确性是生成式东谈主工智能的另一个难点。在新的东谈主工智能指数叙述中,TruthfulQA被用作测试法律硕士真确性的基准。它的 817 个问题(波及健康、法律、金融和政事等主题)旨在挑战咱们东谈主类常犯的失误不雅念。
2024 岁首发布的 GPT-4 在基准测试中得到了 0.59 的最高分,比 2021 年测试的基于 GPT-2 的模子高出近三倍。这么的逾越标明,在给出真确谜底方面,LLM 的性能正在缓缓进步。
东谈主工智能生成的图像如何?要了解文本到图像生成的指数级更动,请稽查 Midjourney 自 2022 年以来在画图《哈利-波特》方面所作念的尽力:

渐进式版块的 Midjourney 如何更动文本到图像的生成
这特殊于东谈主工智能 22 个月的逾越。你以为东谈主类艺术家需要多万古刻才能达到访佛的水平?
讹诈文本到图像模子合座评估(HEIM),对 LLM 的文本到图像生成才气进行了基准测试,测试波及对图像的"内容部署"至极要紧的 12 个关键方面。
东谈主类对生成的图像进行了评估,发现莫得一个模子在总共法式中都推崇出色。在图像与文本的对王人度或图像与输入文本的匹配度方面,OpenAI 的DALL-E 2得分最高。基于Stable Diffusion的黑甜乡般传神模子在质料(像片的传神进度)、好意思学(视觉眩惑力)和原创性方面名次最高。
来岁的叙述会更精彩
您会细心到,这份东谈主工智能指数叙述的死心时刻是 2023 年年底,这一年是东谈主工智能加快发展的震动之年,亦然东谈主工智能发展的地狱之年。事实上,惟一比 2023 年更恣意的年份是 2024 年,在这一年里,咱们看到了Suno、Sora、Google Genie、Claude 3、Channel 1 和Devin 等首要发展恶果的发布。
这些家具和其他一些家具都有可能绝对改革总共这个词行业。而 GPT-5 这个高明的幽魂正掩饰着它们,它有可能成为一个闲居而教化相长的形状,从而合并总共其他形状。
东谈主工智能不会清除,这是细宗旨。从本叙述中不错看出,总共这个词 2023 年的技能发展速率至极快,这标明东谈主工智能只会不断发展,不断缩庸东谈主类与技能之间的差距。
咱们知谈这有好多东西需要消化,但还有更多。叙述还研讨了东谈主工智能发展的缺点,以及它如何影响民众公众对其安全性、实在度息兵德的主张。
敬请期待本系列报谈的第二部分!
走访斯坦福大学关联页面了解更多:
https://hai.stanford.edu/news/ai-index-state-ai-13-charts🔥2024欧洲杯(中国区)官网-登录入口
热点资讯